Member Node Related
1 Error installing SGX driver
-BIOS settings error
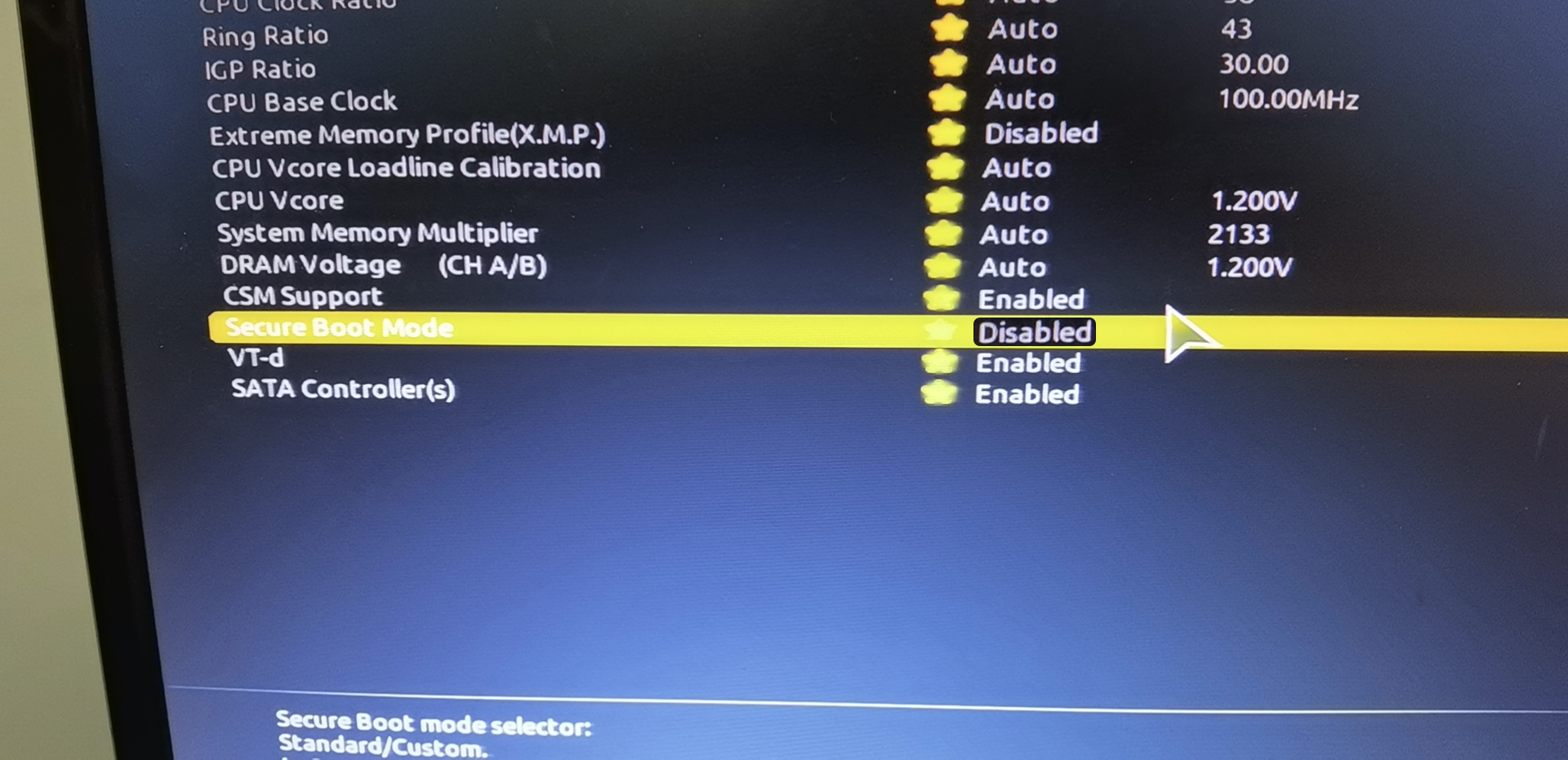
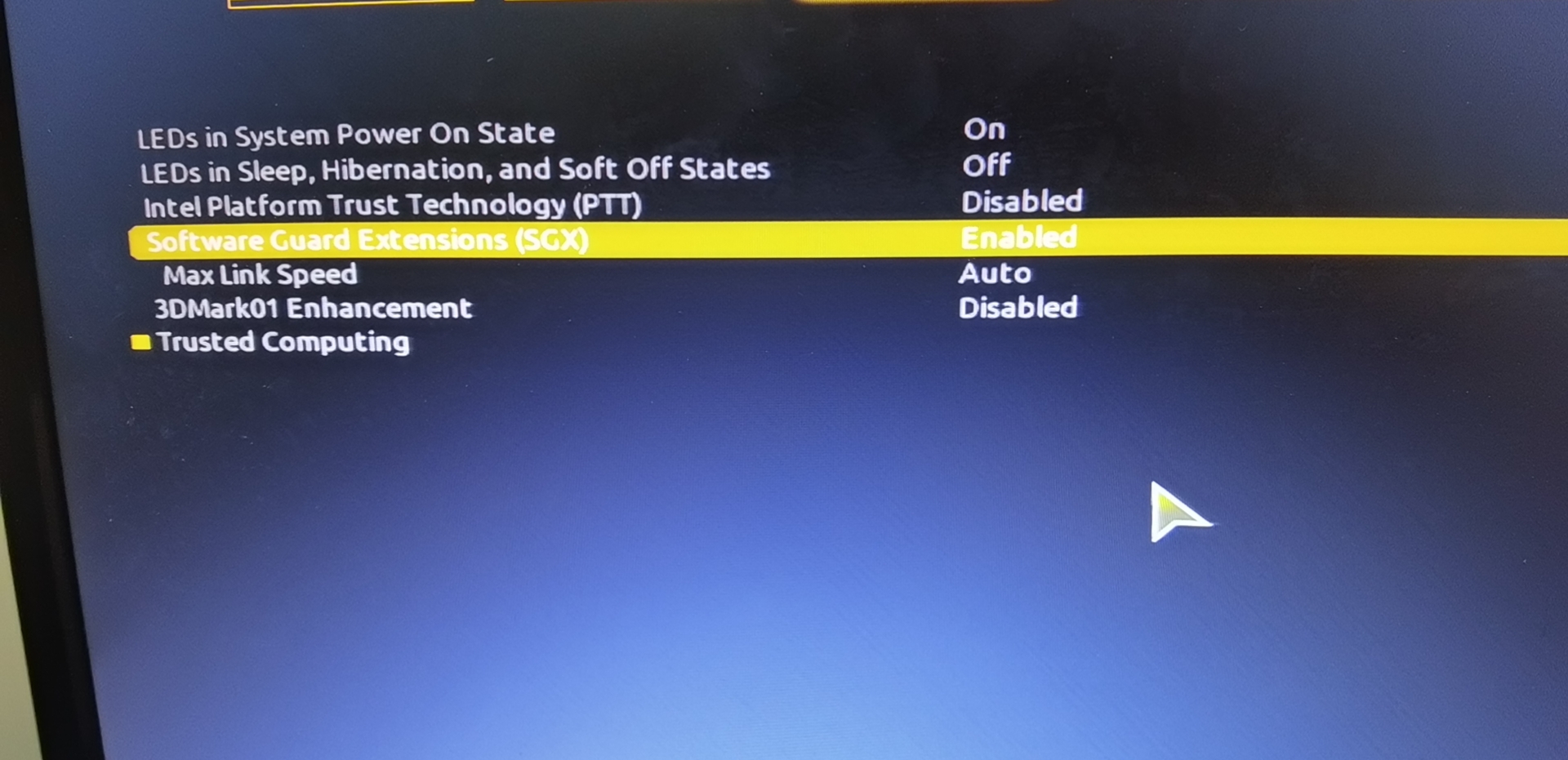
If the following error occurs, you need to check whether the relevant items in the BIOS are set. You need to set secure boot to Disabled and SGX to Enabled. If SGX cannot be set to Enabled, it can be set to software enabled, and after booting into the system, use software to activate SGX.
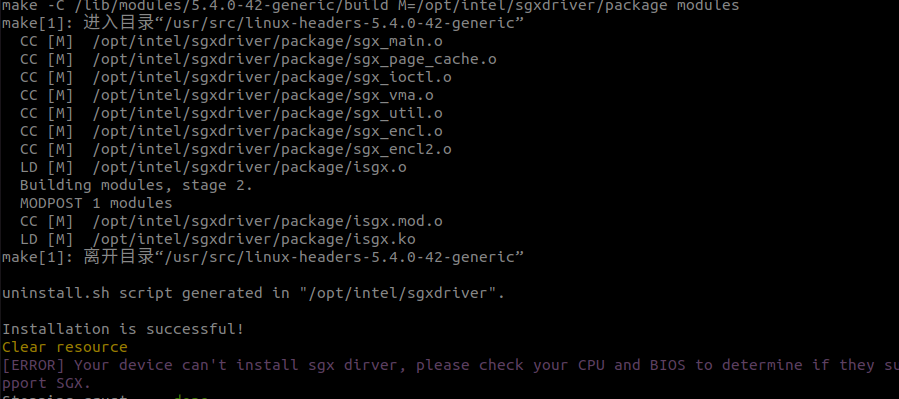
- Network Error
As shown in the figure below, it is a network error, you need to check whether there is a problem with the network connection
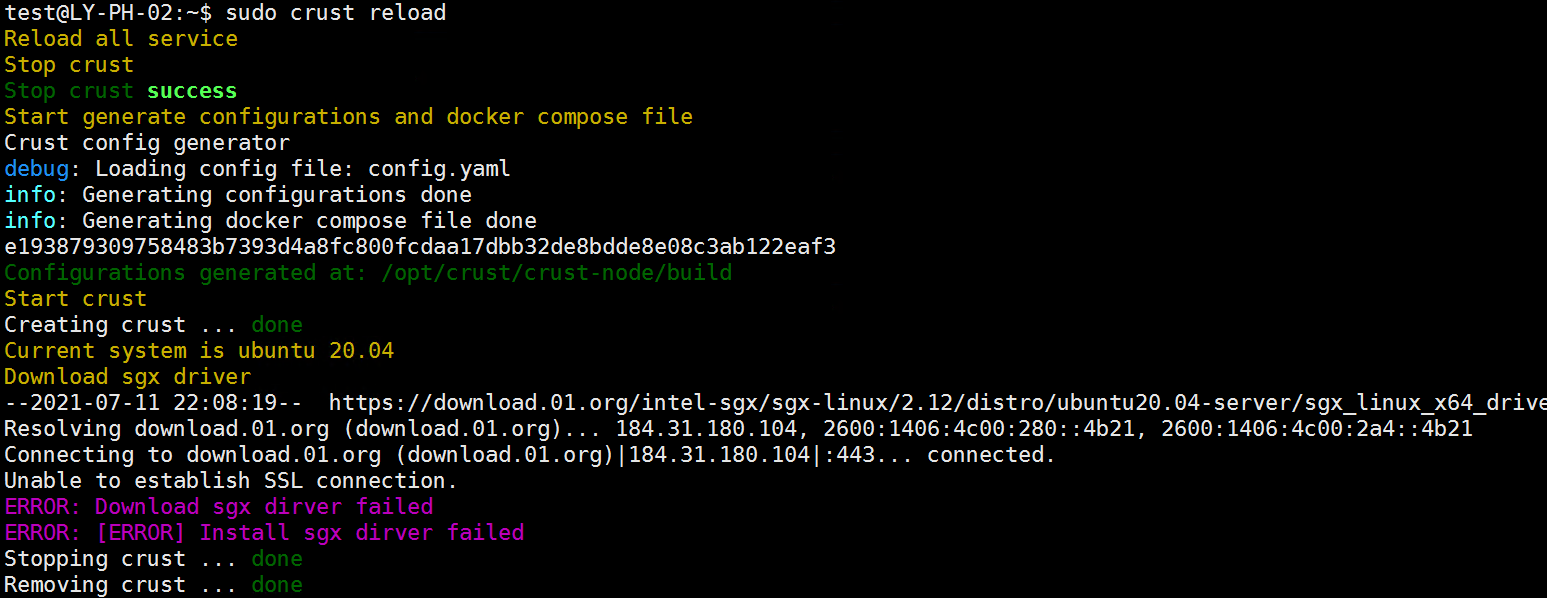
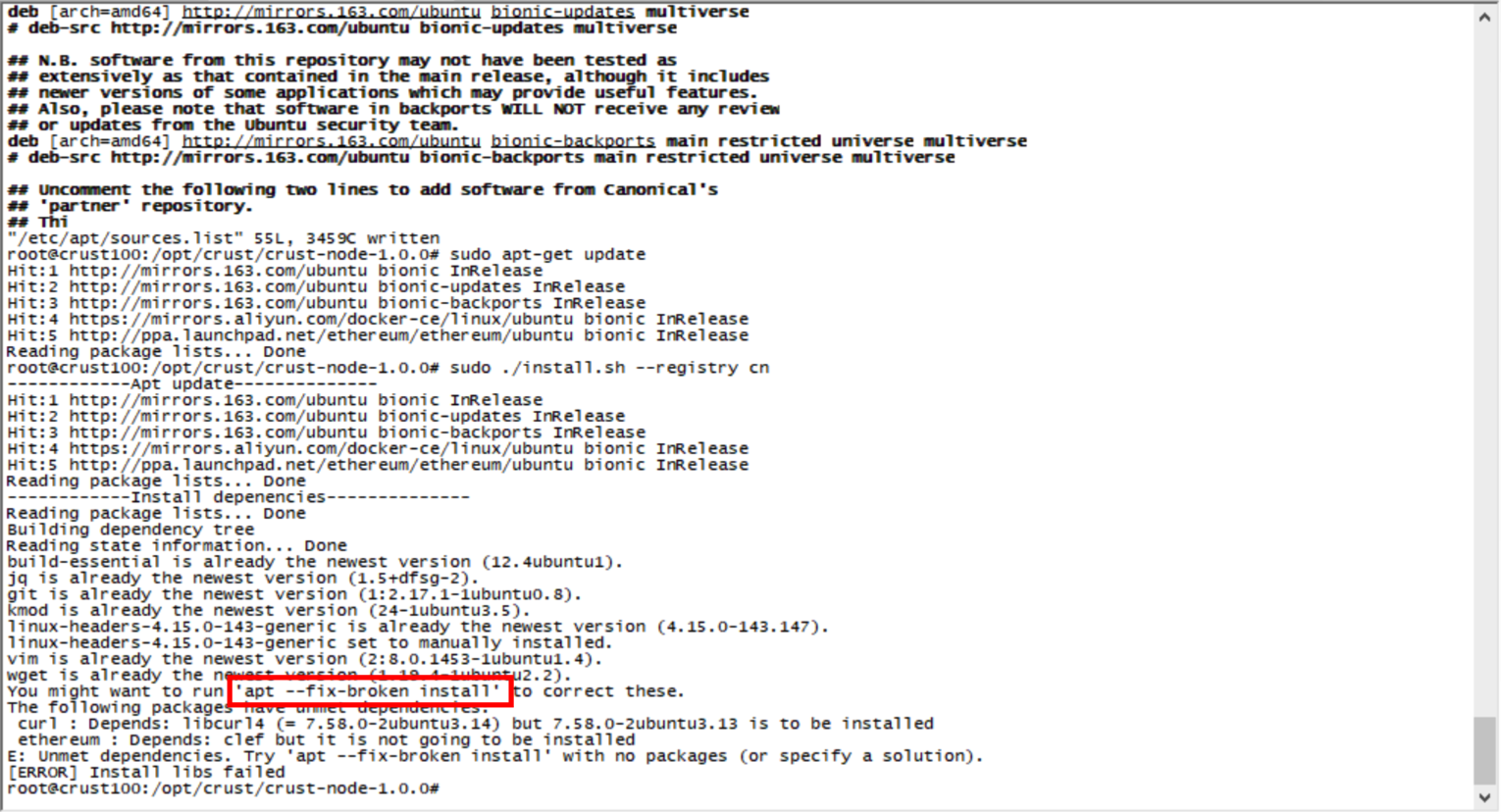
-Install dependent libraries
If the error is shown in the figure below, you need to enter the specified instructions to fix the error according to the error prompt given by the system during installation
-Drive conflict
If you have installed other SGX drivers before, there may be driver conflicts. It is recommended to reinstall the system directly
2 How to mount the hard disk
Points to note before installation:
System disk configuration:
-The program will be installed in the /opt/crust path, please make sure that the system disk has more than 2TB of solid state drive space. If you do not want to use the system disk, but use other solid state drives, please create the /opt/crust directory in advance, and hang the solid state in this directory, pay attention to the read and write permissions of the directory
File disk configuration:
The order file and SRD placeholder file will be written in the /opt/crust/disks/1 ~ /opt/crust/disks/128 directory, depending on how you mount the hard disk. Each physical machine can be configured with up to 500TB of reserved space
-Single mechanical hard disk: directly mount to /opt/crust/disks/1
-Multiple mechanical hard disks (multi-directories): Mount the hard disks to the /opt/crust/disks/1 ~ /opt/crust/disks/128 directories respectively. For example, if there are three hard disks /dev/sdb, /dev/sdc and /dev/sdd, you can mount them to /opt/crust/disks/1, /opt/crust/disks/2, / opt/crust/disks/3 directory. The efficiency of this method is relatively high and the method is relatively simple, but the fault tolerance of the hard disk will be reduced
-Multiple mechanical hard disks (single directory): For hard disks with poor stability, using RAID/LVM/mergerfs and other means to combine the hard disks and mount them to the /opt/crust/disks/1 directory is an option. This method can increase the fault tolerance of the hard disk, but it will also bring about a drop in efficiency
-Multiple mechanical hard drives (hybrid): Combine single directory and multiple directories to mount
You can use the following command to view the specific situation of the file directory mounting:
sudo crust tools space-info
3 Can member nodes use network hard drives?
Can be used, but only supports mounting a single path /opt/crust/disks/1
4 How to add hard disks to the running Member node?
Tip: Adding a hard disk requires restarting the crust service. Restarting sworker will trigger a penalty for invalid workload, which lasts for about 9 hours without gains.
Execute the sudo crust stop sworker command to stop the sworker service
Mount the hard disk that needs to be added to /opt/crust/disks/1 ~ /opt/crust/disks/128
Execute the sudo crust start sworker command to start the sworker service
Execute sudo crust tools change-srd xxx to add srd packaging task
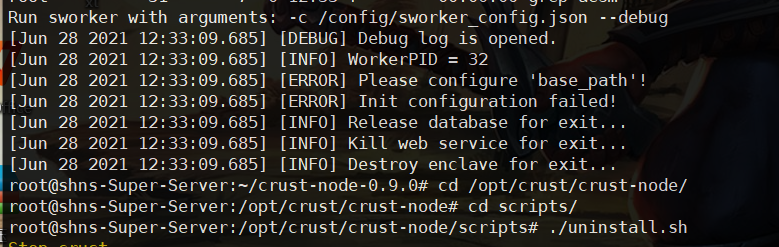
5 Sworker startup error
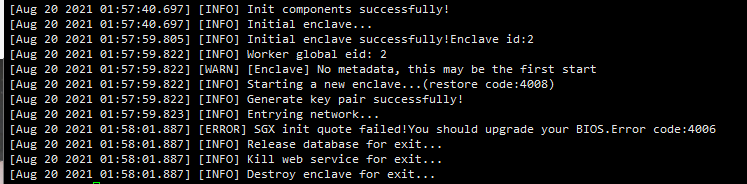
- Upgrade BIOS
If the error is shown in the following figure, the BIOS firmware needs to be upgraded or downgraded, and the version number of the BIOS needs to be adjusted to the appropriate version (upgrade or downgrade according to the specific situation). If it fails, replace the motherboard.
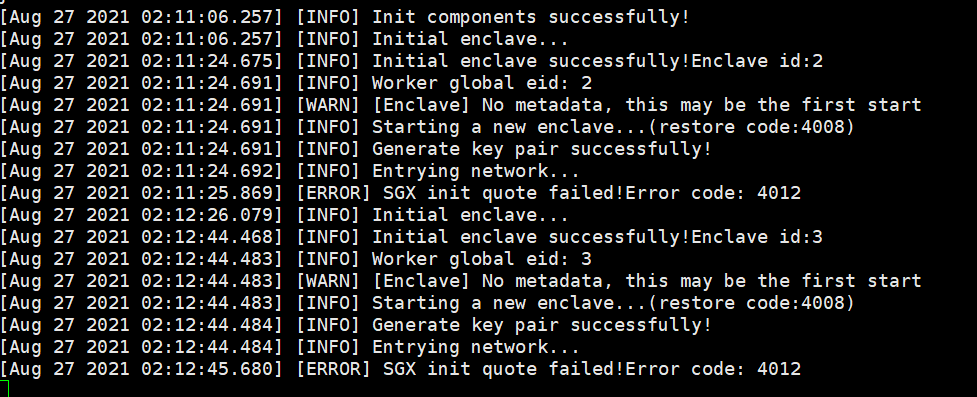
- Unstable network
4012 and AES service problems occur, indicating that the network is unstable, please adjust the network
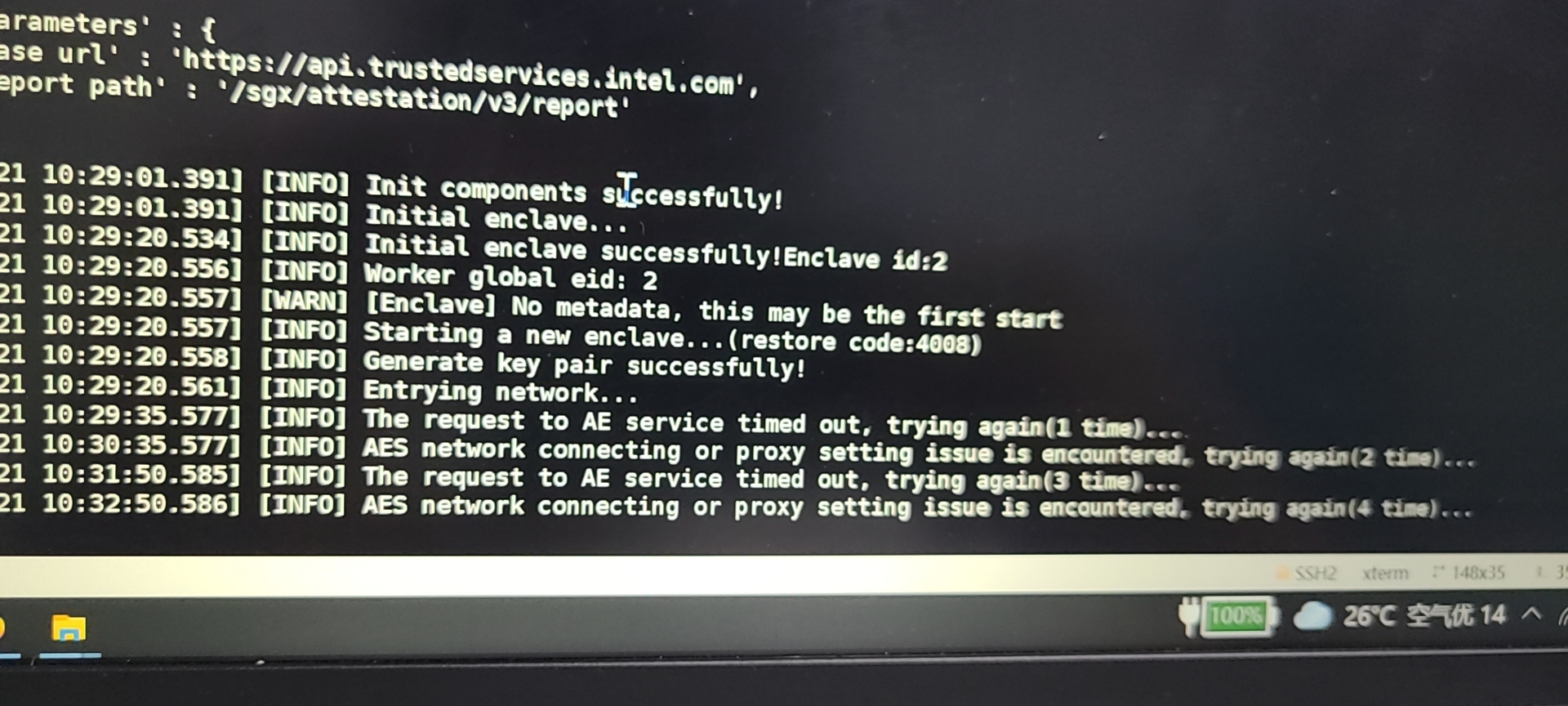 The IAS request failed because the IAS server is unstable. Please try again until it succeeds.
The IAS request failed because the IAS server is unstable. Please try again until it succeeds.
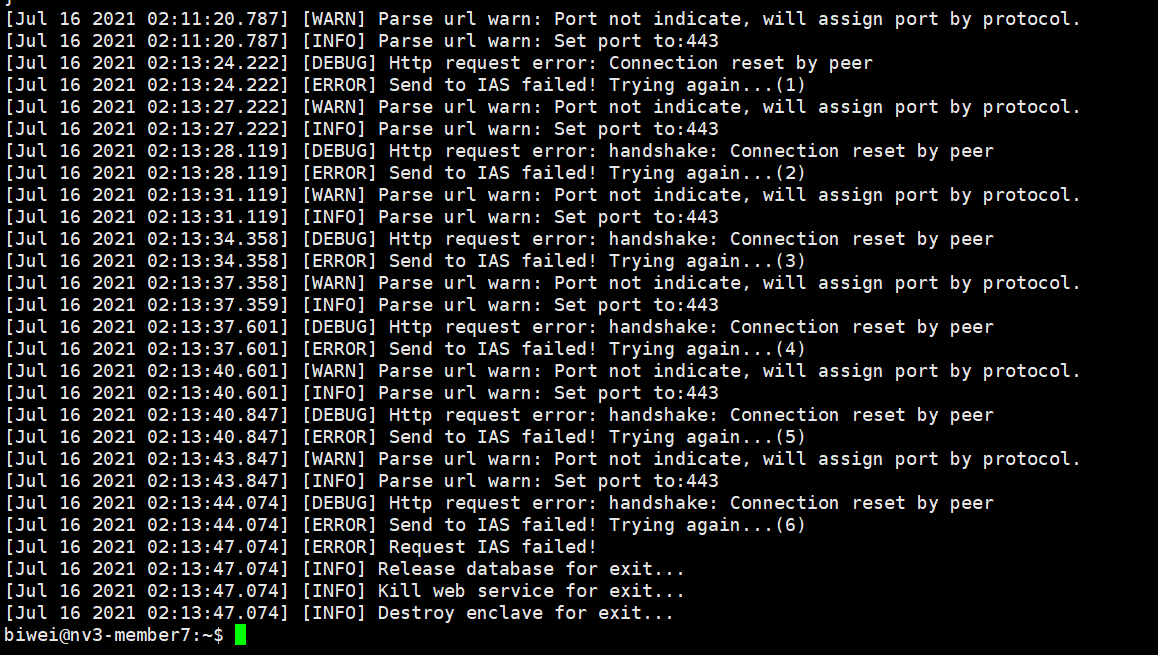
- Configuration error
The error shown in the figure below is because the user has changed the backup configuration, which makes it impossible to restart. Please use the backup of the account configured at the first startup. If you are sure to change the account, please clear all files and reconfigure the node.
 The error shown in the figure below is because you did not follow the steps to set up, please strictly follow the node manual for related operations
The error shown in the figure below is because you did not follow the steps to set up, please strictly follow the node manual for related operations
- Other startup errors
If the above error does not appear, but it still cannot be started, please try to restart several times
6 What is the reason for the error "Inability to pay some fees, e.g. account balance too low" reported in the sworker log?
- Execute sudo crust logs chain to view the log of the chain, and check whether the best block height is consistent with the Apps block height. If it is inconsistent, execute the following command to restart sworker
sudo crust reload sworker
- Confirm whether the account configured by the Member node has a certain number of CRUs
7 sworker log report "Unable to decode using the supplied passphrase"
The account password configured on the Member node is incorrect
8 Hard disk device error
- The following are several common problems caused by unstable disks or improperly configured permissions. If the following errors occur, please check the disk and related read and write permissions
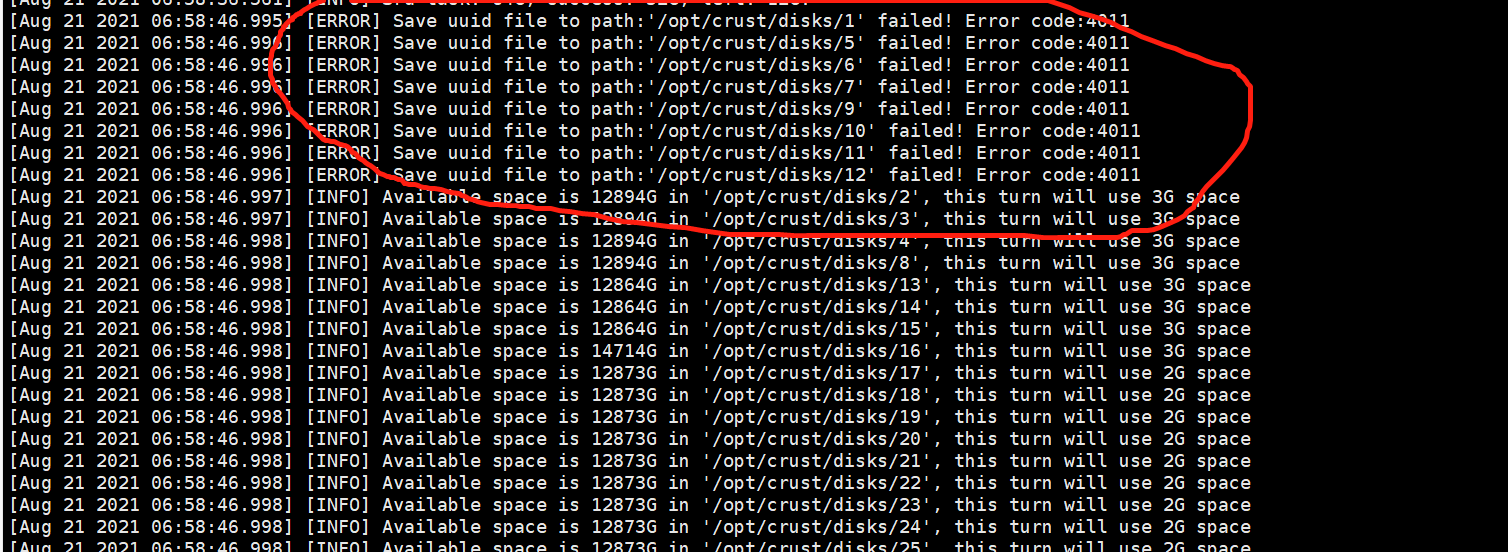
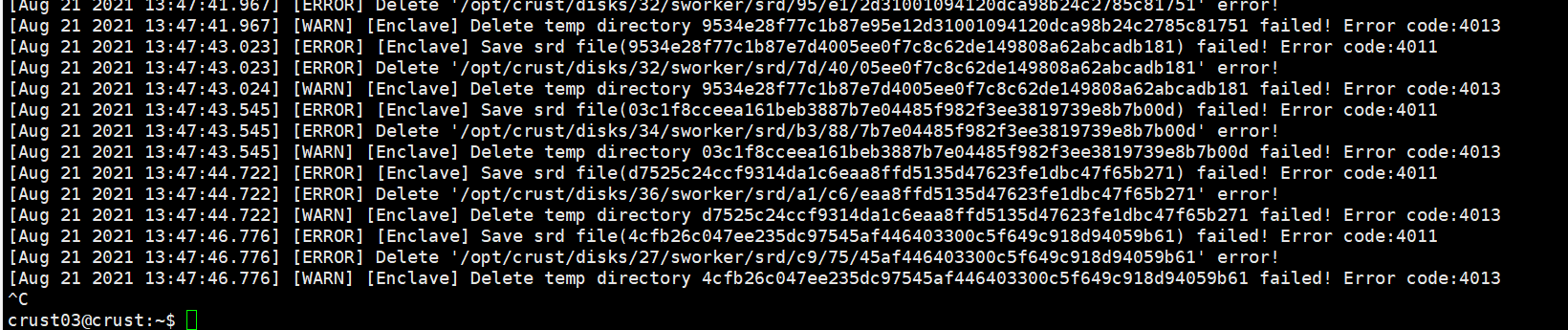
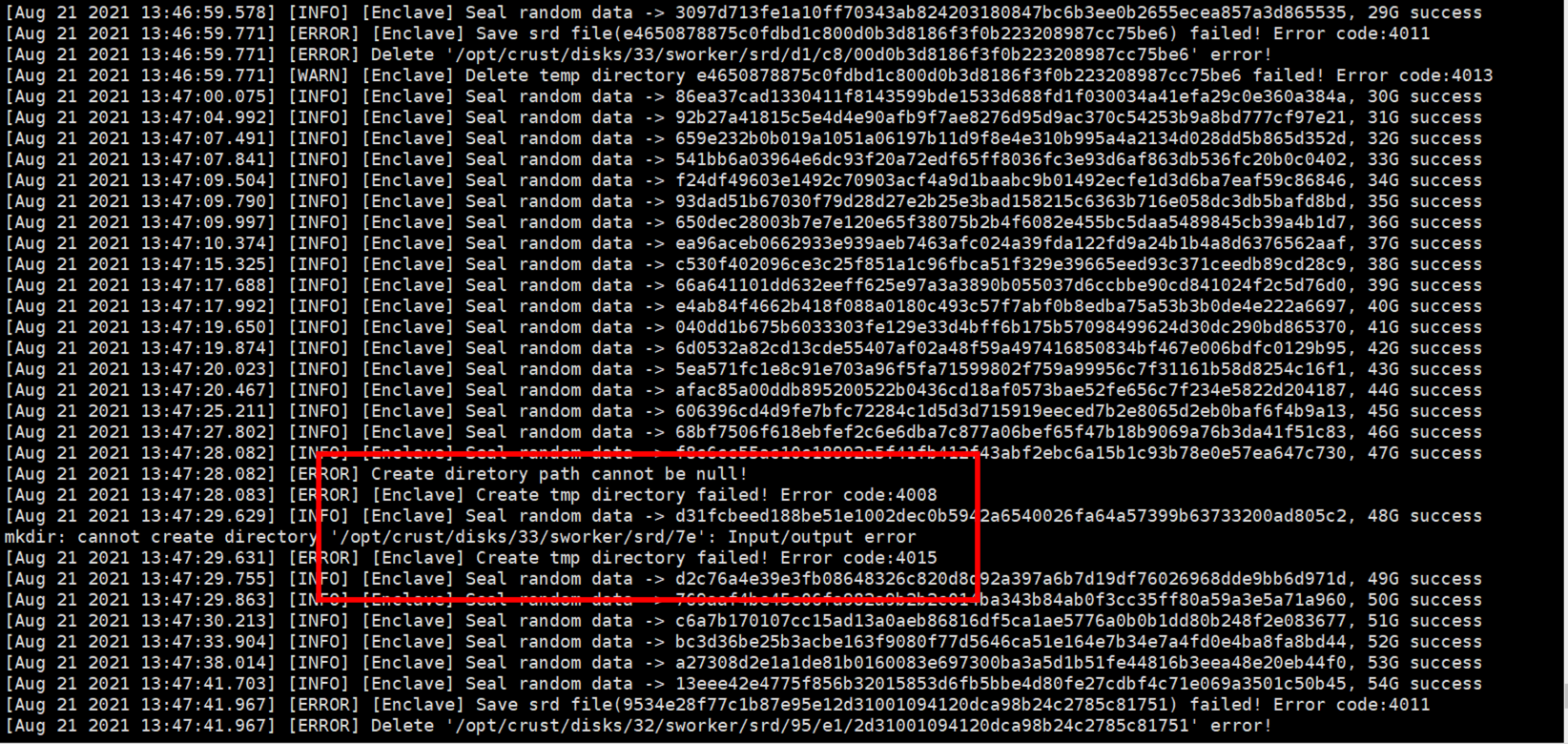
- When checking the workload, it is stuck, indicating that there is a problem with the tracks of some disks, and the disk needs to be tested
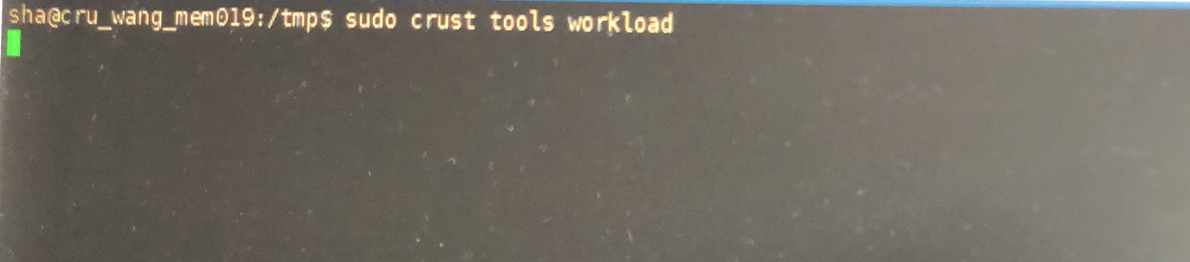
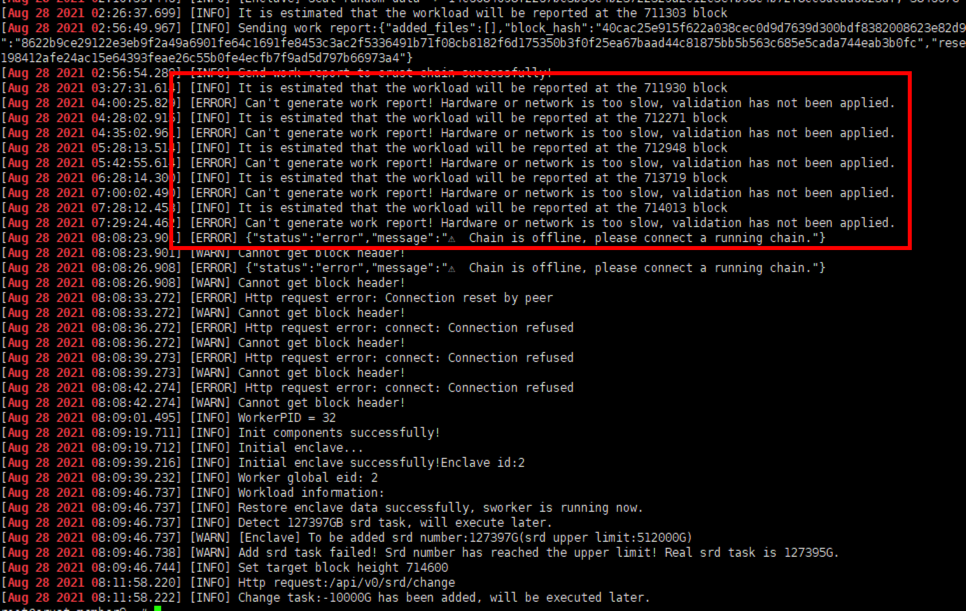

9 Sworker workload reporting error
Use the following command to view the cause of the workload reporting error:
sudo crust logs sworker | grep'WRE'
In most cases, it is caused by unstable chain synchronization, try to improve the network environment
10 Can the encapsulated computing power be cut to another machine for mining?
No, the encapsulated computing power is related to the SGX module, and the hardware key of each SGX module is different
11 illegal reporter
The account configured by the member is duplicated with other members
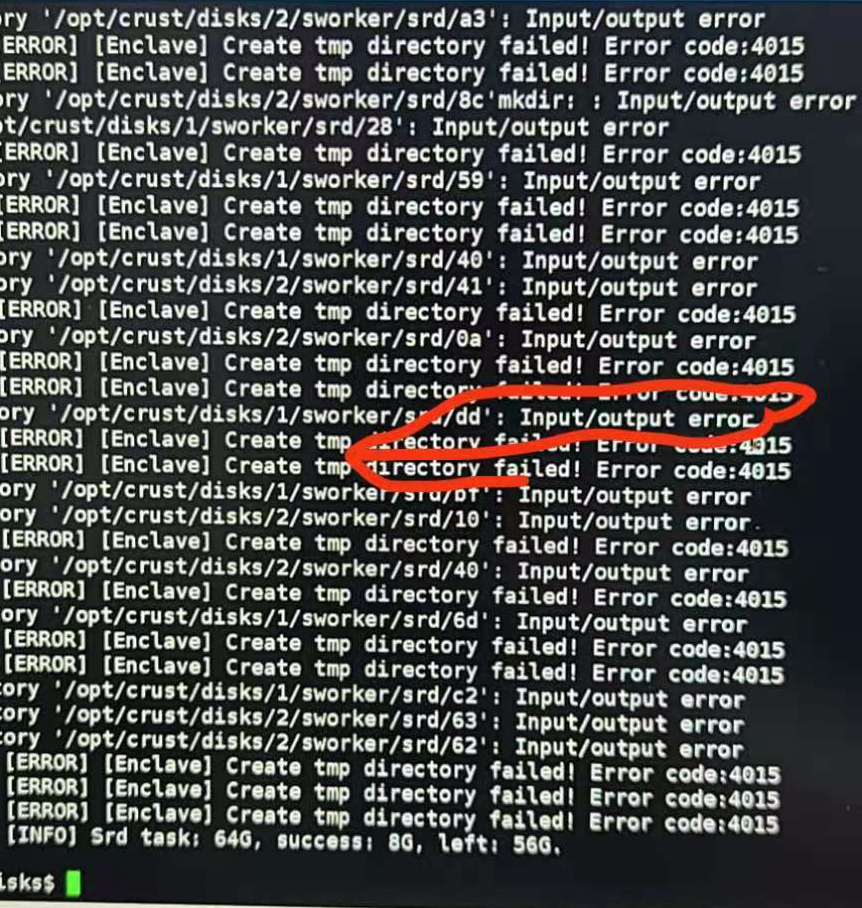
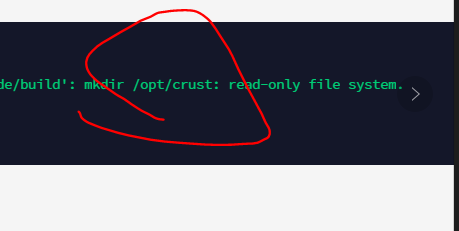
12 Sworker log report "Input/output error"
Disk failure, read and write errors, please check the hardware configuration of the disk, Raid card, power supply, etc.
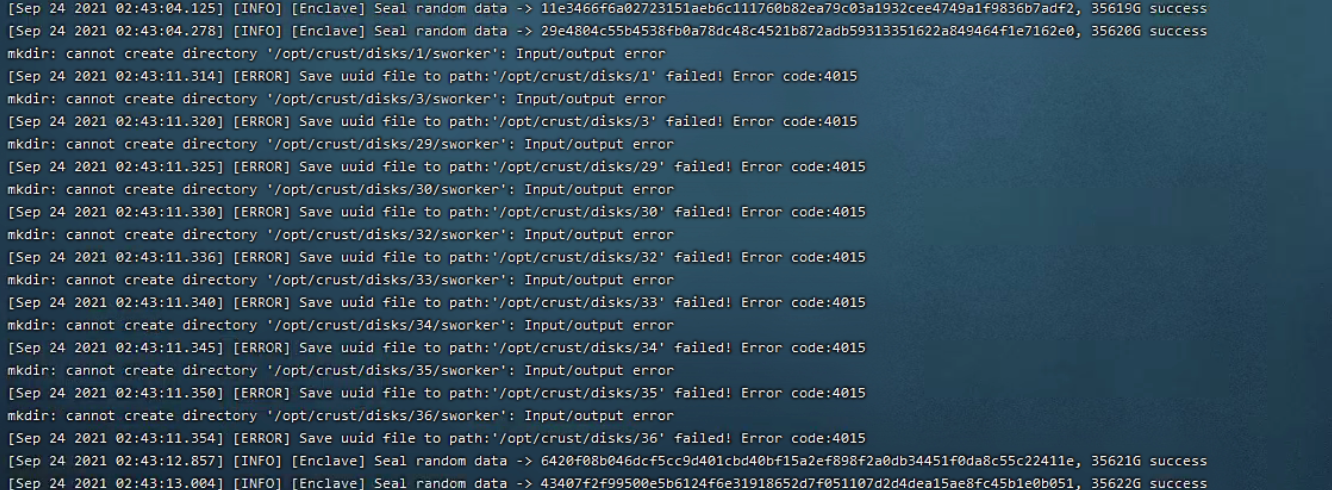
13 Sworker log report "Get srd (hash) metadata failed ,please check your disk. Error code:4016"
If the program fails to retrieve the packaged data, please check the disk read and write failure caused by the hardware configuration of the disk, Raid card, power supply, etc., or the hard disk is not mounted before restarting the computer
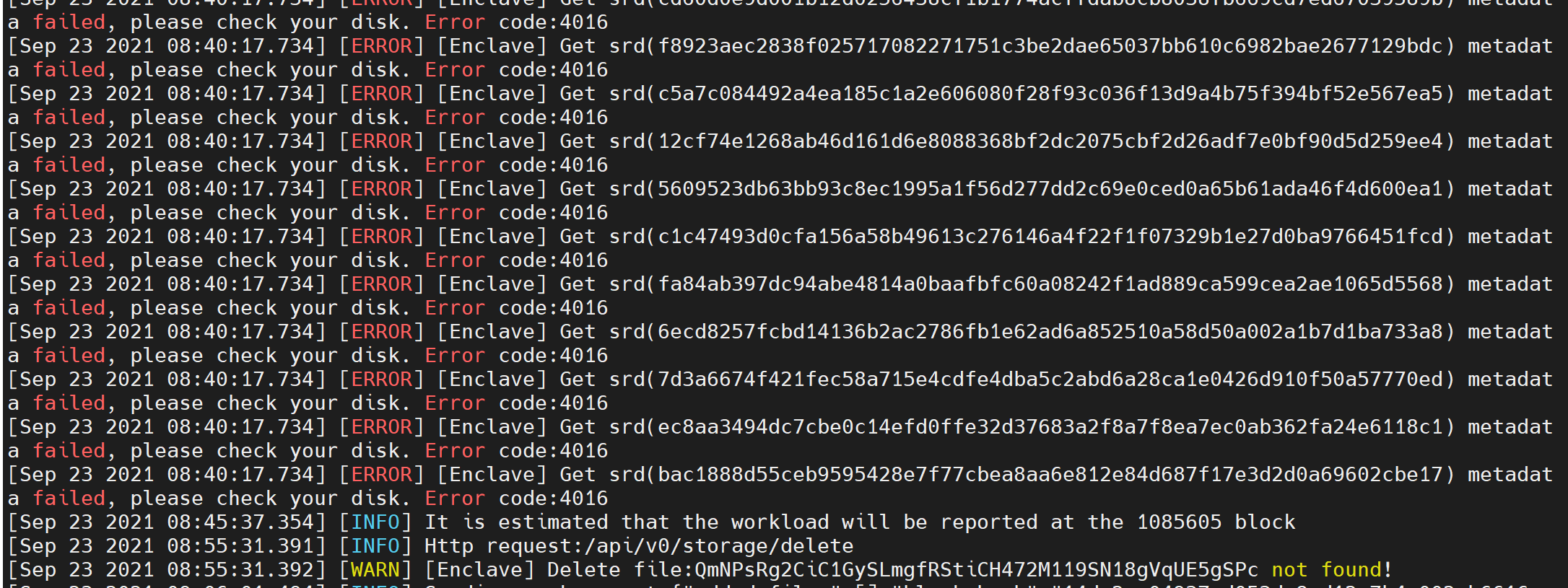
Execute 'sudo crust tools workload' command to check if the sum of "srd_complete" and "disk_available_for_srd" is much smaller than disk_volume, it is recommended to re-srd
The solution is as follows
Ensure that the disk reads and writes normally
Execute 'sudo crust stop sworker' command to stop the sworker program
Execute 'sudo rm -rf /opt/crust/data/sworker' to delete sworker metadata
Format the mechanical hard disk and remount it to /opt/crust/disks/1~128
Execute 'sudo crust reload sworker' command to restart the sworker program
Execute 'sudo crust tools change-srd xxx' command to issue the srd task
14 Sworker log report "...swork.IllegalFilesTransition..."
First of all, if you just quit the group, please check the section "How to change the group of Member nodes?" in this page instead of the current section

Reason:Unstable network causes the expected workload to be sent to be inconsistent with the actual workload
The solution is as follows:
- Keep sowkrer service online
- Execute the following command
#!/bin/bash
account=$(curl http://localhost:12222/api/v0/enclave/id_info | jq .account)
extrinsic_index=$(curl -s -XPOST 'https://crust.webapi.subscan.io/api/v2/scan/extrinsics' --header 'Content-Type: application/json' --data-raw '{"page": 0, "row": 1, "signed": "all", "call": "report_works", "module": "swork", "success": true, "address": '$account'}' | jq -r '.data|.extrinsics[0]|.extrinsic_index')
params=$(curl -s -XPOST 'https://crust.webapi.subscan.io/api/scan/extrinsic' --header 'Content-Type: application/json' --data-raw '{"extrinsic_index": "'$extrinsic_index'", "events_limit": 10, "only_extrinsic_event": true, "focus": ""}' | jq -r .data.params | sed 's/\\//g' | jq .)
added_files=($(echo $params | jq .[6].value | jq -r .[].col1))
deleted_files=($(echo $params | jq .[7].value | jq -r .[].col1))
input_data='{"added_files": ['
for file in ${added_files[@]}; do
input_data="${input_data}\"$(echo $file | xxd -r -p)\",";
done
if [ ${#added_files[@]} -ne 0 ]; then
input_data=${input_data:0:len-1};
fi
input_data="${input_data}], \"deleted_files\": ["
for file in ${deleted_files[@]}; do
input_data="${input_data}\"$(echo $file | xxd -r -p)\",";
done
if [ ${#deleted_files[@]} -ne 0 ]; then
input_data=${input_data:0:len-1};
fi
input_data="${input_data}]}"
curl -XPOST "http://localhost:12222/api/v0/file/recover_illegal" --header 'Content-Type: application/json' --data-raw "$input_data"
15 Sworker log report "...Priority is too low..."
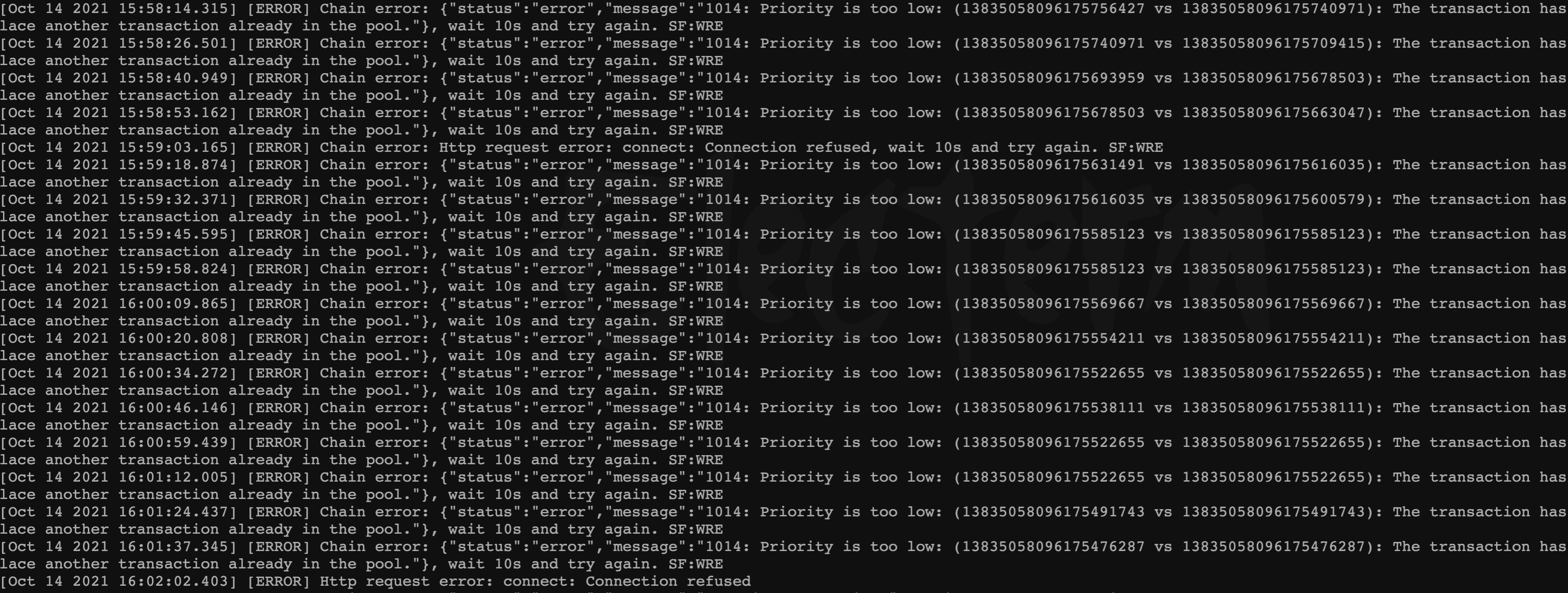
The chain synchronization is unstable due to network problems, and the local block height is lower than the maximum block of the main network
The solution is as follows:
- Option 1 : Increase network bandwidth, configure a fixed IP or reduce the number of member nodes in the same LAN
- Option 2 : Set the chain P2P port, restart the chain service and then configure port forwarding and QoS on the router