工作量
sWorker的工作量有两个部分构成:SRD和有意义文件。本章节将详细介绍这两种工作量的生成、校验等过程。
SRD
生成
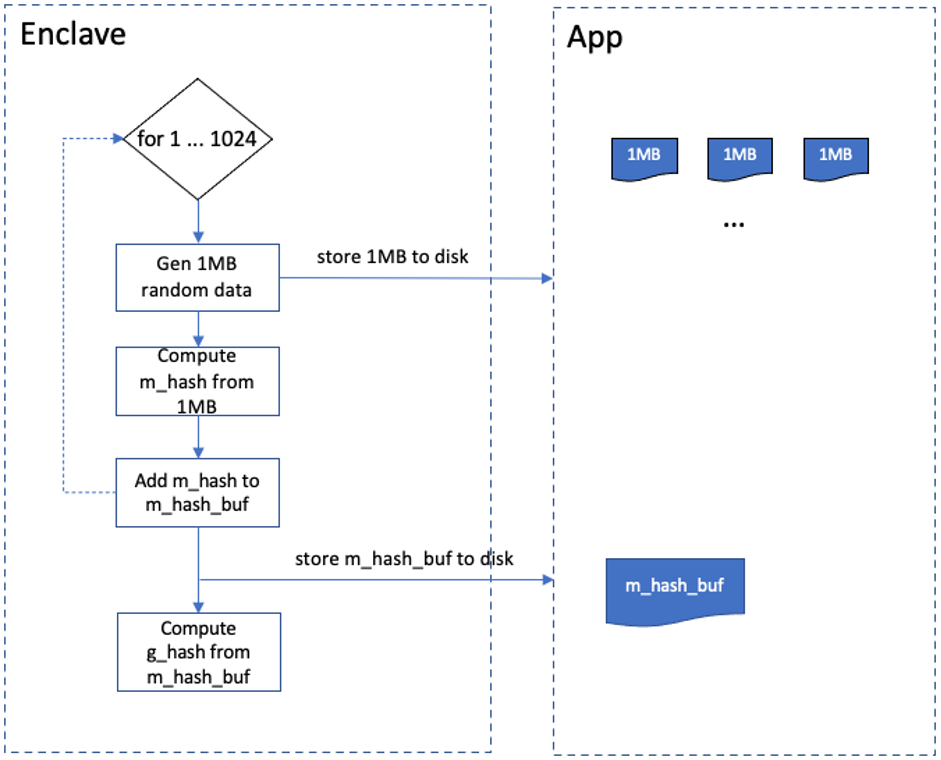
SRD(Sealed Rand Data)是sWorker增加工作量的一种方式。通过SGX的seal方法,sWorker在Enclave中生成随机数据,再通过安全边界将生成的随机数据写入磁盘中。一次SRD可以生成1GB随机文件,具体过程是:Enclave每生成1MB的随机数据会向外存一次,并计算出该1MB的哈希值,记为m_hash,并将其存入m_hash_buf中。重复以上过程1024次,就得到了1GB的随机文件,然后将m_hash_buf存到外部作为这1GB的metadata,再计算出m_hash_buf的哈希值作为这 1GB SRD数据的凭证,记为g_hash,并存放在Enclave内部。以上为1GB的SRD数据产生过程。整个流程如下图所示:
校验
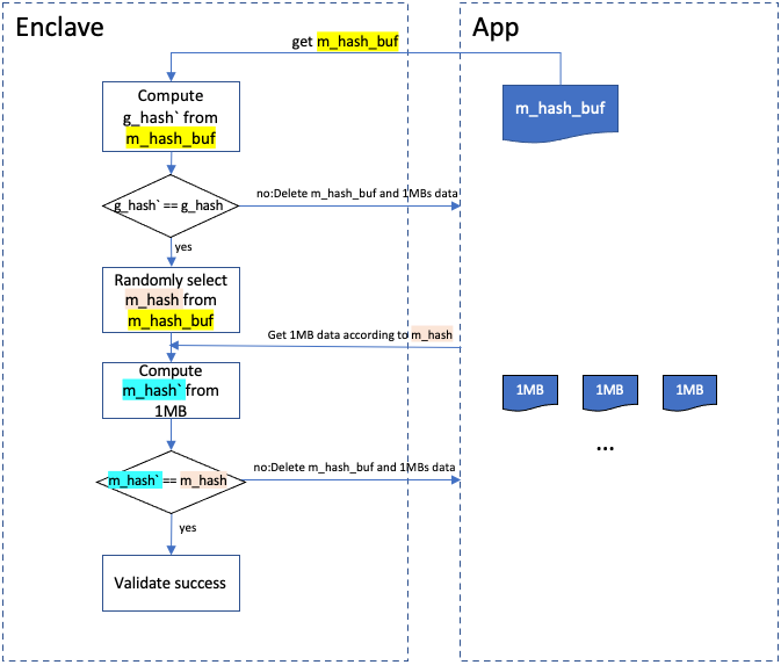
为了防止节点作弊,SRD文件需要被定期抽查。当需要校验某个SRD时,首先将它的m_hash_buf从外部读入Enclave中,计算出它的哈希值---g_hash`,将g_hash`和g_hash进行对比,如果不相等,则校验失败,对应的1GB的SRD数据会被删除;相等则从m_hash_buf中随机选择一个哈希值,记为m_hash,这个m_hash值对应某个1MB的SRD数据,Enclave会将m_hash值对应的1MB数据从磁盘读入,并计算出它的哈希值,记为m_hash`。将m_hash`和m_hash进行对比,不相等则校验失败,删除该1GB的SRD数据,相等则校验成功。SRD的生成速度和机器的硬件性能相关,高性能的CPU、内存和磁盘会大大加快SRD的生成速度。整个流程如下图所示:
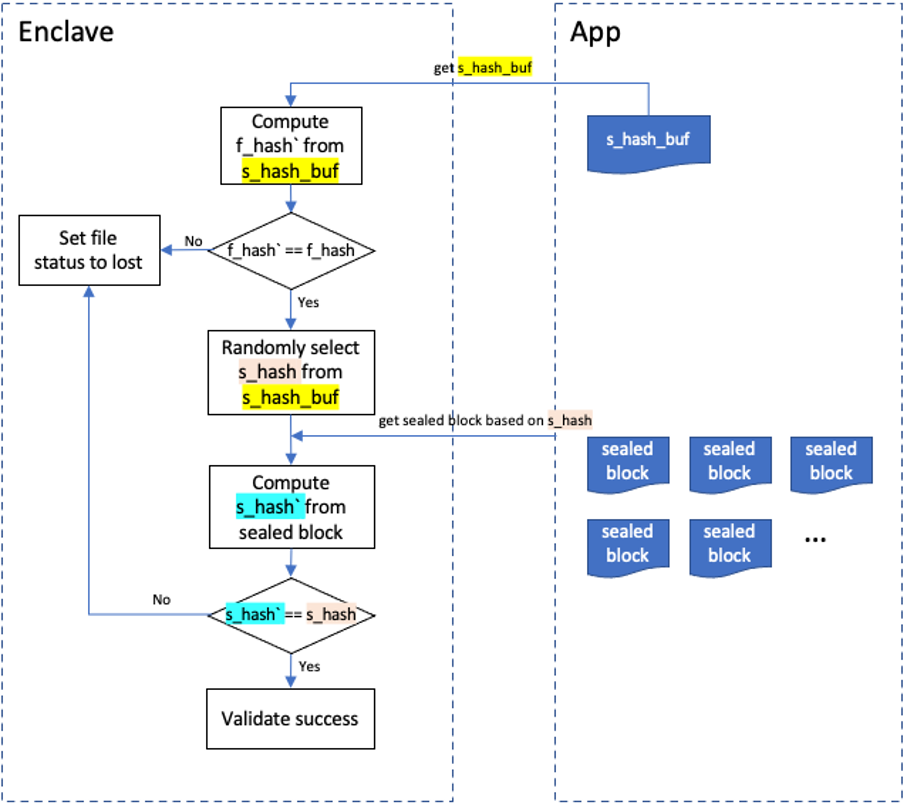
有意义文件
生成
有意义文件是sWorker增加工作量的另一种方式。sWorker使用IPFS作为存储和通信层。
IPFS是一个点对点存储网络,基于DHT协议,每个IPFS节点的数据可以通过网络传输共享给其他的IPFS节点。IPFS会将一个文件拆分为无数个文件块,每个文件都有一个CID(content identity),并且每个文件块中都包含它所需要的剩余文件块的CID,知道了需要获取的CID,IPFS就可以通过DHT协议在网络中不断搜索并获取自己所需要的文件块,直到得到一个完整的文件。
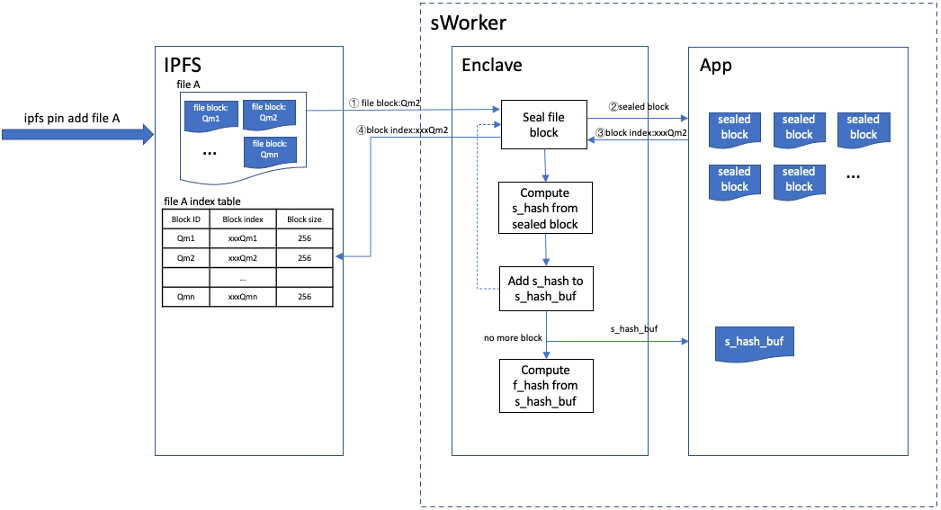
Crust对IPFS进行了略微的修改已适配存储协议,简单来说就是将IPFS接收到的文件块送到sWorker中进行存储和量化,原来IPFS的数据库中存放的不再是原始数据,而是sWorker返回给IPFS的索引,通过索引,IPFS能够从sWorker获取对应的原始数据。 一个文件的存储具体过程:IPFS每获取到一个文件块就发送到sWorker。 sWorker将该文件块进行seal之后得到加密数据sealed_block,并将sealed_block存到硬盘上,生成一个对应的索引block_index,并将其返回给IPFS。 随后计算出sealed_block的哈希值s_hash,将其加入s_hash_buf中。当文件的所有文件块都seal完成之后,sWorker会计算出s_hash_buf的哈希值f_hash,并将s_hash_buf作为文件的metadata存到Enclave外部,f_hash则作为文件的凭证存放在Enclave中。整个流程如下图所示:
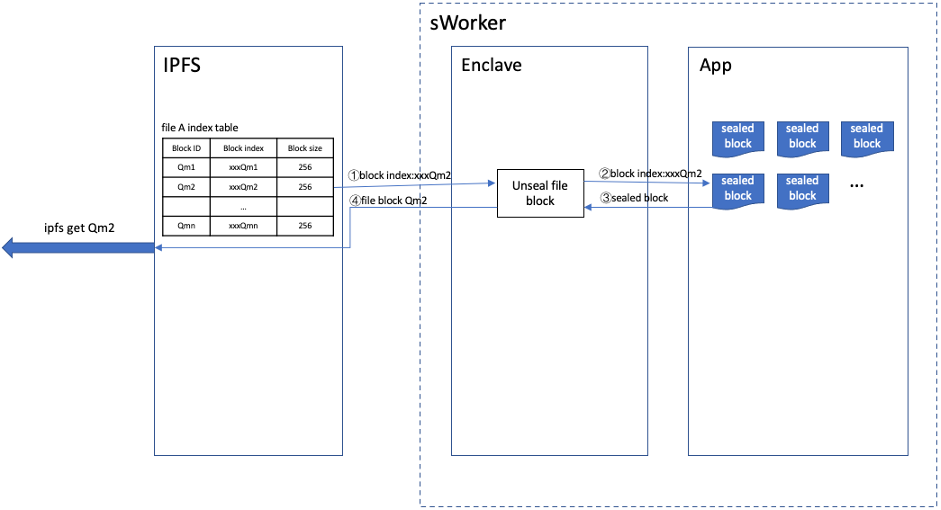
获取
当对某个IPFS文件块的网络请求到来的时候,IPFS通过该文件块的ID找到对应在sWorker中的索引值,IPFS通过该索引去请求sWorker,就能获取到对应文件块的数据。
校验
为了防止存储节点作弊,sWorker会定期抽查文件。从Enclave外部读入s_hash_buf,计算其哈希值f_hash`,对比f_hash`和f_hash,不相等则校验失败,相等则随机选取s_hash_buf中的某个s_hash,该值对应一个具体s_file_block,sWorker从外部将对应的s_file_block读入Enclave中并计算出它的哈希值s_hash`,对比s_hash`和s_hash,不相等则校验失败,相等则成功。校验失败,文件的状态会被设置为“lost”,文件算力会从节点的stake limit中减掉。